In a previous article I explained what Zero Trust (ZT) is about and I positioned it in the overall context of the changing cybersecurity landscape.
This article summarizes the different techniques to enable enterprise networks for ZT. It is important to understand that the enterprise’s strategy for ZT shall drive technology adoption, rather than the reverse. That being said, in most cases, an organization does not need to start ZT from scratch. It is likely that there are already processes and technology adopted that can be taken to a next level, in order to reach the ZT objective.
Foundation for a ZT ready network: dynamic, identity-based access policy and micro-segmentation
Let me start with a brief recall of the main principles of a ZT network.
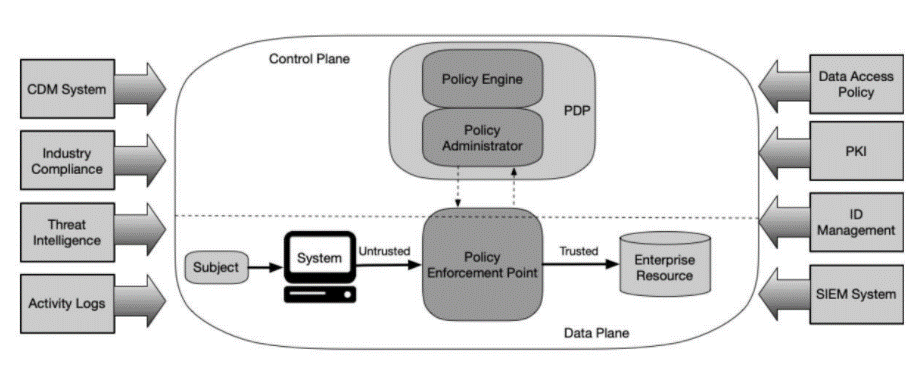
(1) Dynamic, identity-based access policy grants a requester (a ‘subject’ in the vocabulary of National Institute of Standards and Technology, NIST) network access to a resource, no longer by trusting its IP address or subnet, but after checking its identity or profile. Upon its connection attempt, the identity or other characteristics of the requester (user, device or resource) is signaled to a central authentication and authorization service, which acts as Policy Decision Point (PDP). If there is a match (e.g. the credentials of the user on the device are valid or the device’s profile is recognized), PDP dynamically assigns its policy, determining which resources this subject is allowed to access. This dynamic recognition and policy assignment abstract policy from any network construct, like was the case with access policies based on traditional network segmentation by routing instances or VRFs and LAN-segments or VLANs.
(2) Micro-segmentation contains resources in fine-grained, logical groups residing inside or even across the existing network constructs. This improves control of lateral flows, hence reduces the attack-surface of traditional macro-segments. Also, micro-segments decouple security segmentation from any network construct, which usually defines a traditional macro-zone. This makes it possible to define segments following logical criteria, like user groups and roles, device types, application affinities and more.
Synergizing both above principles drastically reduces the burden of adding or moving endpoints. There is no more need for any updates in the network and on firewalls. These updates are known as labor intensive, error-prone, hence often cause long delays before new workloads and applications can be deployed and made available for use.
(3) a ZT model continuously monitors, controls, logs and audits user activity in real time. This provides organizations with a complete picture of who accesses what, and why. When suspicious activity occurs, security teams receive immediate warnings, making it easy to identify and respond to potentially malicious activity.
Identity based access policy
This comes to authorizing a requester to access resources on the network, based on the his identity or profile, rather than on his location in the network. Hence, policies and corresponding rules shall base permissions on user groups or other attributes pertinent to the requester, rather than on IP addresses.
The traditional method to authenticate endpoints to wired or Wi-Fi LAN consists in the IEEE 802.1x standard, using RADIUS as authentication service. Typically, RADIUS is backed by the enterprise’s identity directory service, most often Windows Active Directory (AD). Hereby, the wired or Wi-Fi network access device (switch or wireless access point, respectively) polls the connecting endpoint for its credentials like userid/password or certificate, and forwards these to RADIUS. Upon endpoint authentication, RADIUS acts as Policy Decision Point (PDP) and links the device identity to the segment the device shall be part of, more precisely to its VLAN-id. It returns the VLAN-id as a RADIUS attribute to the network access device. The network access device then dynamically configures the switchport accessed by the authenticated device into the right VLAN.
Beyond IEEE 802.1x authentication based upon endpoint credentials, network vendors enriched authentication criteria by more device specific attributes like MAC address, system name, OS(-version), manufacturer etc. With this technique, most often known as ‘device profiling’, PDP first tries to discover the endpoint’s attributes, then authorizes the endpoint when its attributes match a valid profile and subsequently, instruct the network access to place the endpoint into the VLAN assign to the profile.
Although organizations applying IEEE 802.1x, maybe extended by ‘profiling’, decrease configuration effort by dynamic rather than static VLAN configuration on network access devices, the result is still macro-segmentation. The diagram below illustrates static versus dynamic macro-segmentation.

From macro- to micro-segmentation
The above dynamicity does not address the need for logical segmentation, decoupled from any network topology. This decoupling constitutes the essentials of micro-segmentation as it pushes endpoints into logical groups partitioning one VLAN or even intersecting several VLANs. A common example is a building, where each floor represents one VLAN. This keeps the network topology relatively simple, scalable and ‘easy to oversee’. However, on each floor, there are wired and wireless enterprise laptops, BYOD-devices, printers, facility devices, billboard displays and more. All these categories of endpoints need different authorization, as they need to access different resources. As they all belong to the same VLAN, macro-segmentation is not able to differentiate access policies between these device categories, nor to prevent illegal lateral flows between different groups of devices inside the VLAN. So, an infected laptop could act as ‘man in the middle’, intercept and alter data flowing between a facility device and its server, causing e.g. illegal physical access to a floor, or a blackout.
Therefore, vendors of wired and wireless access devices introduced a new technique. Hereby, the authorization policy of PDP dynamically assigns tags to endpoints, according to their identity or profile. PDP then instructs PEP to ‘place the tag’ on the network access port each time a device connects. Also, at initialization of the PEP, PDP downloads access lists to PEP, as part of the authorization policy. These access lists use the tags as source and destination, so it permits or denies flows on membership of a logical group, rather than on any network context, as illustrated by the diagram below. Back to the previous example, the infected laptop (say A2) becomes unable to impose itself as ‘man in the middle’, hence cannot tamper traffic from and to the facility device (say A1).

Micro-segmentation and its deployment models
One main goal of ZT is to reduce the large attack surfaces that exist in traditional segmentation. It rapidly deemed unrealistic to do this by splitting the traditional segments formed by VLANs and VRFs into many smaller VLANs and/or VRFs, ending up in one VLAN per resource in the extreme case. This would proliferate firewalls, or at least firewall interfaces, to unaffordable and unmanageable amounts. Otherwise stated, traditional firewall separation is not suited for micro-segmentation.
Vendors in different domains of network and security technology early noticed opportunities to develop solutions and offerings addressing the demand for micro-segmentation. This often caused customers’ network and security teams to become overwhelmed with information on this topic. It is important to understand that micro-segmentation solutions have been developed from different areas of technology: compute and virtualization, network and security. This led to four different approaches and corresponding deployment models shown in the below diagram. Those are greatly determined by the core business of the offering’s vendor.

(1) Agent based
Each individual endpoint receives its policy from a central policy engine, acting as PDP. Therefore, the endpoint runs an agent that contains a ‘software’ firewall that receives its ruleset from the PDP. Some vendors use thin agents that leverage on the firewall built-in in the operating system, like Windows firewall or IPtables for Linux/UNIX. Others use agents imposing their own software firewall. Agent-based solutions mostly include an application dependency mapping (ADM) capability. When set to ‘learning mode’, ADM discovers ‘who talks what to whom’, a great help for defining the policies, and reaching the goal of ‘blocking mode’, i.e. when policies come into action. Examples of products for these deployments are Illumio Core and Guardicore Centra.
(2) Hypervisor based
This agent-less deployment is part of a hypervisor-based (as opposed to fabric-based) Software Defined Network (SDN). The virtualization platform provides virtual networks, overlaying the physical network. A distributed logical firewall (DLF) runs in the hypervisor kernel, one instance in front of each virtual server. Hence, each individual virtual server has its own protection perimeter, excluding uncontrolled lateral flows inside the logical overlay networks. The policies are defined in the SDN-controller and pushed to the DLF. Examples of hypervisor based SDN, providing micro-segmentation are Vmware NSX, Nuage VSP and Juniper Contrail, in addition to Open Source solutions based on Open vSwitch (OVS). It is a great solution for micro-segmentation in data centers but needs to be complemented by another solution for micro-segmenting ‘users’ and ‘client devices’.
(3) Network based
These techniques may sound like a paradox, as they instruct the network to abstract segmentation … from any network construct. However, network infrastructure from most leading vendors is able to provide this abstraction. Roughly, there are three flavors: downloadable access-lists (DACL), inline tagging and Software Defined Network (SDN).
Following successful authentication of an endpoint (e.g when device’s attributes match a known profile or valid identity) PDP sends a DACL as RADIUS attribute to the network access device, that configures it on the port where the authenticated endpoint connects, for the duration of this connection. This DACL permits or denies ingress or egress traffic on the port. Ports connected to endpoints belonging to the same logical group receive a similar DACL. This creates (micro-)segments with a logical significance, rather than segments bound to a network construct. It requires the access device to support the RADIUS ‘access-list’ attribute.
Inline tagging, like applied by Cisco Trustsec, leverages also on RADIUS. As part of endpoint authentication, RADIUS imposes a tag – Trustsec’s ‘Scalable Group Tag’ (SGT) in Cisco terminology – to the port of the access device that the endpoint connects to. The tag represents the endpoint’s micro-segment, e.g. the endpoint’s group-id. The ingress access device inserts the tag into the ethernet frames, sent by the connected endpoint. The egress access device filters the received frames according to its policy matrix, as imposed by the PDP. The policy determines the permitted flows for a given sender/receiver tag combination. Inline tagging is done by hardware, which makes this technique proprietary. Inline tagging also needs a complementary protocol – proprietary as well – so signal tag-to-IP bindings over network domains that lack inline tagging capable hardware, i.e. layer-3 networks and also layer-2 networks from other vendors.
The most generic technique for decoupling segmentation from network topology is Software Defined Network (SDN). The above described hypervisor-based technique leverages on hypervisor-based SDN, whereas in ‘fabric-based’ SDN, the network components themselves abstract segmentation from network. The control and data plane of the physical network or ‘underlay’ are even not ‘seen’ by the network operator (except in rare cases of ‘deep’ troubleshooting), let alone by the applications. SDN builds overlays using tunneling techniques like VXLAN and Geneva. These overlays constitute the logical data plane, and represent segments with logical significance, e.g. application groups/tiers in a data center context, or group-id’s or device types in a campus context. The SDN controller centrally creates and maintains filters for flows between and also inside the overlays. These controls can be combined with redirection to a firewall, especially when Next Generation (NextGen, NG) capabilities like Intrusion Detection and Identity Awareness are required to complement packet filtering.
Not surprisingly, these network-centric techniques for micro-segmentation originate from the leading vendors of network equipment, including SDN-fabrics. Examples are Cisco ACI (in data center) and DNA (in campus/branch), Arista EOS, Huawei Cloud Fabric and more.
(4) Traffic redirection for inspection
This technique forces traffic from the endpoint’s access device over a secure tunnel to the PEP for inspection. This is much similar to how Wi-Fi forwarding commonly works, in that lightweight access points (LWAP) forward traffic of their connected devices to a Wi-Fi controller, enabling central policy control. Not surprisingly again, this deployment model is common to vendors originating from the Wi-Fi area, like Meraki, or from the security area, like Fortinet.
Although all vendors will claim their solution to be complete and comprehensive, each approach has by its very nature its attractiveness, challenges and sweet spot, as summarized in the table below.

… and what about ZTNA?
Some organizations claim ZT is equivalent to Zero Trust Network Access (aka, ZTNA, next-gen VPN access). However, although ZTNA may address part of the requirements of the ZT framework, it does not provide the entire ZT enablement.
ZTNA was launched by John Kindervag from Forrester Res. in 2010 as acronym for ‘Zero Trust Network Architecture‘, when introducing the concept of ZT. Confusingly, ZTNA was thereafter hi-jacked by the community of vendors offering solutions to securely access ubiquitous private, corporate applications by ubiquitous users. These solutions came under the umbrella of ZTNA standing for ‘Zero Trust Network Access‘, also known as Software Defined Perimeter (SDP). In this meaning, ZTNA could better have been named ZTAA, standing for Zero Trust Application Access. ZTNA fulfills ZT’s requirement of identity based, explicit permission for subjects to access resources. Otherwise stated, ZTNA excludes any implicit permission.
Therefore, a prime use of ZTNA is replacement of traditional remote access VPN. Whereas VPN permits an authenticated remote user to access the enterprise network, ZTNA offers more granularity by limiting the authenticated user to access one or more specific applications, whereas other applications stay hidden to him. In addition, ZTNA continuously checks the posture of the endpoint. Should a change occur on the endpoint, violating current ZTNA access policy, ZTNA will disconnect it from the application.
In the example below, two users moving across HQ, branch and home connect to a ZTNA service relaying them only to those applications they are permitted to use.

In a ZTNA environment, a user connects to a ZTNA service, either from an endpoint with a ZTNA agent, or agentless. In the latter case, ZTNA service acts as proxy for the endpoint’s browser, limiting ZTNA to applications supported by the browser: HTTP(S), RDP, SSH and some more. After identity check by the enterprise’s identity store, or by an Identity Provider (IDP), the agent establishes a secure tunnel to the ZTNA gateway. ZTNA presents a single signon (SSO) panel with the user’s authorized applications. ZTNA gateway then opens the data plane for the user, solely to the selected application.
Organizations shall at least consider combining ZT with ZTNA. ZT brings the users, devices, applications and resources, based on their identity or profile, into their micro-segment. Thereafter, the user connects to ZTNA and requests access to his specific application. After positive identity check, all user traffic to this application is routed and inspected through ZTNA, until sign-out, with possibility for session recording and real-time termination upon unpermitted user actions.
Transition from legacy security to Zero Trust
An organization shall start with defining its ZT strategy, then select technology, approach and architecture to implement it, followed by incremental roll-out.
Define ZT strategy
Today the Zero Trust Architecture published by US National Institute of Standards and Technology (NIST) is widely accepted as reference for ZT. However, it leaves room to interpretation and to the degree of strictness of the measures that shall implement ZT. E.g. protection against lateral contamination may range from imposing barriers between differently sized (micro-)segments to full prohibition of any lateral flow, both between servers, users and devices.
Therefore, a good starting point is to analyze the current cybersecurity risks and their impact, to which the enterprise IT is exposed. To mitigate these risks, the ZT enabling elements can be defined and prioritized.
- Ensure visibility of devices, resources and users connected to the network.
- Improve network segmentation, stop implicit trust and prevent unauthorized lateral flows by adopting micro-segmenting data center and cloud, campus and Operational Technology (OT) networks.
- Prevent unauthorized and malicious devices from accessing the wired and Wi-Fi network, and only permit devices authenticated by valid credentials or valid profile.
- Phase-out IP address-based policies in favor of identity-based policies, e.g. by adopting Next Gen firewalls imposing identity awareness (user-id, app-id).
- Implement continuous security information and event monitoring and logging. Consolidate this on a SIEM system, with meaningful reporting and dashboarding, configured to the needs.
- Encrypt data in transit and at rest, conform to regulatory and other requirements.
Below is a non-exhaustive list of decisions to be taken and helping to define the strategy driving ZT.
How to obtain an up-to-date endpoint inventory and flow table? Before embarking in the (micro-)segmentation initiative, the organization must know what to segment. The most accurate way is to run a discovery tool, often in concert with the PDP, capturing device-specific info from any connected endpoint. This device discovery results in an up-to-date inventory, which in turn facilitates endpoint classification into logical groups. Obviously, the more critical the endpoint (e.g. a business-critical application server), the smaller its group. A harder task is to build the current flow matrix and determine which of those flows are needed to run the business. Firewall log analysis takes time and will not show flows inside the current macro-segments. To obtain the full flow matrix, Application Dependency Mapping (ADM) tools may be of great help in view of intended micro-segmentattion.
How to define (micro-)segments? Once the endpoints are discovered, classified and assigned their criticality and the legal, required flows are determined, the organization has to define (micro-)segments. The extreme approach of confining any endpoint of the enterprise, at any location, to its own micro-segment and attack surface, protects this endpoint against any offender. Obviously, this approach is practically unfeasible, due to the huge administrative burden and cost. Hence, it is likely to have different attack surface sizes, in function of the criticality of the resource to be protected. Critical compute components and data are typically protected in small, maybe even individual micro-segments, while larger logical segments, decoupled from any network construct, will host a class of endpoints, user groups or device types. This often ends up in many micro-segments to be created, each one standing for an attack surface. The good news is that in ZT, endpoints as they appear, move and disappear, are dynamically assigned to these micro-segments
How to dynamically push endpoints into their (micro-)segment? Logical segmentation by making PDP aware of user groups defined in the enterprise’s Directory Service (most commonly Windows Active Directory, AD) is a quick-win to segment all endpoints. This classifies servers and users according to their identity. A decision to take is whether or not to extend identity based segmentation to unauthenticated devices, i.e. those not having credentials like user/password or certificate. If this is desired, a technique has to be decided upon in order to dynamically segment endpoints based on attributes determining their nature or function, e.g. device name or type, vendor or more, in short, their profile.
How to monitor endpoints and flows as part of ZT? An essential principle ZT is to maintain visibility into the activities and behaviors of users and applications within the environment. As risk does not disappear once initial authentication and authorization are achieved, continuous logging is key. A well-designed SIEM can provide the level of deep visibility required to ensure an endpoint or user remains trustworthy throughout its cycle. Continuous collection of log data and telemetry, human alarm triage, and investigation of security analytics is an essential part of any ZT.
Select technology to deploy ZT strategy
As seen above, an enterprise has to select one of the four deployment models to transform its network to ZT. These could be complemented by adopting ZTNA, when it comes to further securing user access to applications. As there is no ‘best’, it comes to evaluating which approach best fits the enterprise’s ‘as-is’ network and the already in-place security measures, in order to minimize disruptiveness when rolling-out ZT.
Rarely, an organization needs to enable ZT on its network from scratch, as there is probably already technology in place that ZT can leverage on.
Implement ZT
Implementing ZT is most often a gradual process. One can start with any of the key elements: identity-based access policy, (micro-)segmentation, Zero Trust Network Access (ZTNA), visibility and monitoring, encryption. Most often, securing critical applications and their data is assigned highest priority, such that ZT is first implemented in the hybrid hosting environment: public and private cloud, as well as traditional data center.
Conclusion
Move from static, IP-address-based policies to dynamic, identity-based ones, segment more granularly, improve monitoring, logging and visibility are common denominators of Zero Trust’s mantra: ‘never trust, always verify’. Each enterprise has to fit them into its IT security strategy. However, as there is no ‘one size fits all’ and specific requirements vary from one enterprise to the other, quite some customization is needed when developing the blueprint for ZT. In addition, this blueprint is likely to leverage on already in place security practices and infrastructure. Finally, ZT has to be considered a continuous journey, rather than a final destination. A ZT model perceived today as ideal nevertheless needs continuous improvement as threats, technology, external and internal requirements don’t stop from changing.
Complementary reading
Below link points to an excellent article from Zentera. It outlines the principles and tenets of Zero Trust without any ‘own’ commercial or marketing content.